
Και το όνομα αυτού: Ryzen


Στις 22 Φεβρουαρίου 2017 η AMD κάλεσε τον τύπο σε ένα event που πολύ ευφάνταστα ονομάζονταν “Ryzen 7 Release”. Στο οποίο όχι μόνο μάθαμε λεπτομέρειες σχετικά με την νέα αρχιτεκτονική (Summit Ridge) αλλά και επιβεβαιώθηκαν πολλές πληροφορίες που γνωρίζαμε ήδη από τις φήμες. Η 1η γενιά των Ryzen (Εμπορικό Όνομα) αποτελείται από 3 σειρές. Η χαμηλότερη είναι η Ryzen 3 (αν σας θυμίζει την i3 της Intel θα έχετε δίκιο) η οποίο αποτελείται από 4c/4t τσιπάκια σε πολύ χαμηλές τιμές. Η μεσαία σειρά είναι η Ryzen 5 που αποτελείται από 4c/8t και 6c/12t τσιπάκια και αναλόγως υψηλότερη τιμή. Στην κορυφή κάθονται οι Ryzen 7 οπού και τα 3 μοντέλα είναι 8c/16t. Το σκεπτικό της AMD σε σχέση με τα χαρακτηριστικά και τις τιμές ήταν η εξής. Οι Ryzen 3 θα έχουν τιμές Pentium – χαμηλών i3 με επιδόσεις i5. Οι Ryzen 5 προσφέρουν επιδόσεις ανάλογες των μέσων προς ψηλών i7 σε τιμές ανάλογες των i5. Όσο για τους Ryzen 7 κοιτάνε στα ίσια του ακριβότερους i7 καθώς και κάποιους Xeon σε τιμές των χαμηλών i7. Και για την διαθεσιμότητα? Ryzen 7 από 15 Μαρτίου, Ryzen 5 από αρχές Απριλίου και Ryzen 3 από μέσα καλοκαιριού. Οπότε από τις πρώτες πληροφορίες όλα δείχνουν άκρως υποσχόμενα, ιδίως κιόλας αν επιβεβαιωθούν όλα όσα υποσχέθηκε η AMD.
Επισκόπηση της αρχιτεκτονικής
Οι περισσότερες από τις πληροφορίες προέρχονται από το συνέδριο HotChips στις 21 Αυγούστου 2016 στο οποίο και η AMD άνοιξε τα χαρτιά της σχετικά με την νέα της αρχιτεκτονική, ακόμα τότε ονομαζόμενη ZEN.

Στόχος της AMD ήταν η αύξηση των εντολών ανά κύκλο ρολογιού (Instructions Per Clock – IPC) κατά τουλάχιστον 40% σε σχέση με την αρχιτεκτονική Bulldozer ενώ παράλληλα να μειωθεί η κατανάλωση ενέργειας. Κοινώς μιλάμε για μια δραματική αύξηση της αποδοτικότητας.

Ας ξεκινήσουμε από τα βασικά. Την φωτογραφία του die, ευγενική παραχώρηση της ίδιας της AMD κατά την μέρα της επίσημης ανακοίνωσης.

Ένας σύγχρονος x86 επεξεργαστής που αποτελείται από πυρήνες χωρισμένους σε 2 ομάδες των 4 όπως φαίνεται και στο die shot. Αυτές τις ομάδες η AMD τις ονομάζει CCX (Core Complex). Κάθε CCX αποτελείται από τους 4 επεξεργαστικούς πυρήνες, την L2 και την L3 cache.


Κάθε CCX έχει συνολική επιφάνεια 44mm2 και διαθέτει 512KB L2 cache / πυρήνα και 8MB L3 cache κοινή και για τους 4 πυρήνες τους CCX. 2 τέτοια CCX στο ίδιο die αποτελούν στο την σειρά Ryzen 7. Ομοίως 2 CCX με ένα ή δύο πυρήνες απενεργοποιημένους ανά CCX αποτελούν τους Ryzen 5 και με 2 πυρήνες απενεργοποιημένους ανά CCX ή ένα ολόκληρο CCX και χωρίς πολυνηματισμό κάνουν τους Ryzen 3.
Πυρήνας Ryzen
Αν πάμε ακόμα πιο βαθιά θα δούμε ότι πυρήνας είναι ένας αρκετά συμβατικός x86 που φεύγει από τις πρωτοτυπίες της Bulldozer που την χαντάκωσαν και μοιάζει περισσότερο στην συνταγή της Intel που την έφεραν στην κορυφή τα τελευταία 10 χρόνια. Εδώ βλέπουμε και το πρώτο σημείο υπεροχής έναντι στην Intel όμως.
Η αρχιτεκτονική Summit Ridge είναι πλήρως επεκτάσιμη στα μέτρα την κάθε εφαρμογής. Από ένα χαμηλής ενέργειας και κατανάλωσης chip για φορητή συσκευή με μόλις ένα CCX με τους μισούς πυρήνες ενεργοποιημένους ή ένα CCX χωρίς πολυνηματισμό για τελικό αποτέλεσμα 2c/4t μέχρι ένα τεράστιο chip με 8 CCX πάνω στο ίδιο die για server με αποτέλεσμα 32c/64t χρησιμοποιούν την ίδια βασική αρχιτεκτονική. Ως άλλα τουβλάκια Lego η AMD μπορεί να προσθέτει επιπλέον μονάδες σε ένα chip, η να έχει πολλαπλά chip στην ίδια συσκευασία και να ανεβάζει τις επιδόσεις ανάλογα. Η Intel προς το παρών δεν μπορεί να το κάνει αυτό. Η αρχιτεκτονική Kaby Lake αν και εξαιρετική και πάρα πολύ αποδοτική, βγαίνει μόνο με 2 και 4 πυρήνες, με ή χωρίς πολυνηματισμό. Οτιδήποτε πέρα από 4 πυρήνες χρησιμοποιεί την παλαιότερη αρχιτεκτονική Broadwell-E η οποία είναι μόνο η σμίκρυνση της Haswell στα 14nm.


Στο σχηματικό διάγραμμα βλέπουμε τον πυρήνα να είναι χωρισμένος σε 2 μέρη. Το μπροστά μέρος (front end) με μπλε χρωματισμό και το πίσω μέρος (back end) που είναι όλος ο υπόλοιπος. Στο μπροστά μέρος έρχονται οι εντολές από την μνήμη στον πυρήνα, ενεργοποιούνται οι προβλέψεις μονοπατιού και οι εντολές αποκωδικοποιούνται σε μικρο-εντολές (micro-ops) πριν μπουν σε μία ουρά micro-op.
Κάθε ένας από του πυρήνες της Summit Ridge έχει αυτόνομες και ιδιόκτητες μονάδες επεξεργασίας ακέραιων αριθμών και αριθμών κινητής υποδιαστολής. Σε αντίθεση με τον Bulldozer που είχε κάθε πυρήνας μία μονάδα ακεραίων αριθμών αλλά κάθε 2 πυρήνες μοιράζονταν μια μονάδα αριθμών κινητής υποδιαστολής δημιουργώντας τοπική συμφόρηση, κάτι που τελικά χαντάκωσε όλη την αρχιτεκτονική.
Η κόκκινη περιοχή είναι μέρος του back-end και χειρίζεται τις εντολές βασισμένες σε ακεραίους όπως πράξεις ακεραίων, επαναλήψεις (loops), φορτώσεις και αποθηκεύσεις σε μνήμη. Η πορτοκαλί περιοχή αναλαμβάνει τις πράξεις αριθμών κινητής υποδιαστολής, που συνήθως χρησιμοποιούνται σε μαθηματικές πράξεις. Και οι 2 μονάδες επεξεργασίας έχουν αυτόνομους και ανεξάρτητους χρονοπρογραμματιστές.
Στον κλάδο των ακεραίων (integer) αριθμών συναντούμε 4 ALU (Arithmetic Logical Unit) και 2 AGU (Address Generation Unit). Στην μεριά των αριθμών κινητής υποδιαστολής συναντούμε 2 128bit FMA (Fused Multiply-Add) μονάδες για επιτάχυνση της πράξης του πολλαπλασιασμού. Επίσης βλέπουμε ότι υπάρχει ξεχωριστό μονοπάτι για τις προσθέσεις και τους πολλαπλασιασμούς ότι δεν πραγματοποιούνται πράξεις πολλαπλασιασμού. Όμως λόγο του περιορισμένου εύρους, οι 256bit AVX εντολές πρέπει να διαχωριστούν ανάμεσα στις 2 FMA μονάδες προκειμένου να εκτελεστούν.
Πλέον είναι ξεκάθαρο ότι έχουμε να κάνουμε με ένα μεγάλο βήμα σε σχέση με την Bulldozer μίας και έχουμε τους διπλάσιους υπολογιστικούς πόρους για ακέραιους και κινητής υποδιαστολής αριθμούς. Τώρα, συγκρίνοντας με τις αρχιτεκτονικές Broadwell και Skylake τις Intel, τα πράγματα περιπλέκονται. Οι 4 ALU της AMD είναι παρόμοιες αλλά όχι ίδιες. Κάποιες εντολές πρέπει να επεξεργαστούν από συγκεκριμένη ALU μίας και μόνο μία από τις τέσσερις διαθέτει πλήρη πολλαπλασιαστή. Ομοίως μόνο μία διαθέτει σύστημα διαίρεσης. Προσθέσεις και αφαιρέσεις μπορούν αν εκτελέσουν και οι 4. Φυσικά, όσο πιο περίπλοκη είναι μια ALU τόσο πιο αργή γίνεται, οπότε σε σύγκριση με την Intel η υπεροχή της εκάστοτε αρχιτεκτονικής θα εξαρτάται από την αλληλουχία εντολών προς εκτέλεση.
Περιπλέκοντας ακόμα περισσότερο τα πράγματα, η AMD δηλώνει ότι 6 εντολές μπορούν να σταλούν ανά κύκλο ρολογιού στις 10 μονάδες επεξεργασίας (4 ALU, 2 AGU, 4 FP). Η Broadwell και Skylake μπορούν να στείλουν 8 εντολές ανά κύκλο. Τέσσερις από αυτές πάνε στις AGU (Η Skylake διαθέτει 2 AGU γενικού σκοπού και 2 ειδικών χρήσεων). Οι άλλες 4 ALU είναι μικτής λειτουργίας κινητής υποδιαστολής και ακεραίων αριθμών.
Η Intel ομαδοποιεί τις επεξεργαστικές μονάδες πίσω από 4 θύρες ονόματι 0, 1, 5 και 6. Και οι 4 θύρες διαθέτουν μία ALU ακεραίων. Η θύρα 0 επιπλέον διαθέτει μια μονάδα AVX FMA, ένα διαιρέτη και μια μονάδα διακλάδωσης. Η θύρα 1 διαθέτει μία επιπλέον μονάδα AVX FMA αλλά όχι και διαιρέτη. Αυτό σημαίνει ότι σε ένα κύκλο ρολογιού ο επεξεργαστής μπορεί να δρομολογήσει είτε 2 AVX FMA εκτελέσεις είναι μία διαίρεση και μια AVX FMA. Αλλά δεν μπορεί να κάνει ταυτόχρονα και διαίρεση και 2 AVX FMA.
Στην ουσία αυτό σημαίνει ότι σε ένα κύκλο, η Summit Ridge μπορεί να κάνει 4 πράξεις ακεραίων και 2 πράξεις κινητής υποδιαστολής ταυτόχρονα. Η Skylake όμως μπορεί να κάνει 4 πράξεις ακεραίων το οποίο θα έπιανε και τις 4 θύρες μην αφήνοντας την δυνατότητα να γίνει καμία πράξη κινητής υποδιαστολής. Από την άλλη όμως και η Skylake και η Broadwell μπορούν να κάνουν ταυτόχρονα και 4 πράξεις ακεραίων και 4 πράξεις διευθύνσεων ταυτόχρονα. Η Summit Ridge μπορεί να κάνει μόνο 2 πράξεις διευθύνσεων ταυτόχρονα.
Fetch And Decode
Fetch

Ο ασύγχρονος αποκωδικοποιητής εντολών αναλαμβάνει να γεμίζει τις ουρές εκτέλεσης των υπολογιστικών μονάδων παρακάτω. Και εδώ, η AMD έκανε σημαντικές αλλαγές σε σχέση με την Bulldozer. Όπως συνηθίζεται σήμερα στους x86 επεξεργαστές, η Ryzen αποκωδικοποιεί της εντολές σε μικρο-εντολές (micro-ops) οι οποίες προγραμματίζονται και εκτελούνται μέσα στον επεξεργαστή. Στην Bulldozer, επαναλαμβανόμενες εντολές (όπως επαναλήψεις) έπρεπε συνέχεια να λαμβάνονται από την μνήμη και να αποκωδικοποιούνται. Στην Summit Ridge, υπάρχει μια cache με χωρητικότητα 2000 micro-ops έτσι ώστε τέτοιες επαναλαμβανόμενες δομές εκτέλεσης να παρακάμπτουν το στάδιο της αποκωδικοποίησης. Η Intel πρώτη είχε υλοποιήσει ένα παρόμοιο μηχανισμό με την αρχιτεκτονική Sandy Bridge το 2011.
Αυτός ο μηχανισμός συνδυάζεται και με μια πολύ εξυπνότερη πρόβλεψη μονοπατιού. Οι προβλέψεις μονοπατιού σκοπό έχουν να μαντεύουν ποιες εντολές θα εκτελεστούν μετά από μια διακλάδωση στον κώδικα του προγράμματος πριν φτάσει να εκτελεστεί το σημείο απόφασης. Εάν γίνει σωστή πρόβλεψη, τότε οι διασωληνώσεις του επεξεργαστή μένουν γεμάτες. Εάν όχι, τότε πρέπει να αδειάσουν οι διασωληνώσεις και ουσιαστικά να χαθεί ένα μέρος της δουλειάς που έγινε μέχρι εκείνο το σημείο.
Η πρόβλεψη μονοπατιού της Summit Ridge είναι εξυπνότερη και μαντεύει σωστά περισσότερες φορές. Και όταν αποτυγχάνει, το ενεργειακό και χρονικό πέναλτι είναι μικρότερο. Πλέον η ανάνηψη από λάθος πρόβλεψη γίνεται μόλις σε 3 κύκλους ρολογιού. Η AMD περιγράφει τον μηχανισμό πρόβλεψης μονοπατιού ως ένα νευρωνικό δίκτυο επειδή βασίζεται σε αλγορίθμους μηχανικής μάθησης ονόματι Perceptrons για την λήψη απόφασης. Στο διάγραμμα κυκλώματος είναι το μπλοκ Hash Perceptron.
Οι perceptron είναι μια ενδιαφέρουσα επιλογή για πρόβλεψη μονοπατιού γιατί μπορούν να παρακολουθούν πολλαπλές καταστάσεις ταυτόχρονα έτσι ώστε να καταλάβουν εάν ένα μονοπάτι θα ακολουθηθεί ή όχι. Αυτό τους δίνει το πλεονέκτημα, ιδίως σε μεγάλες δομές επανάληψης. Και η αρχιτεκτονική Bulldozer λέγεται ότι χρησιμοποιούσε perceptrons για την πρόβλεψη μονοπατιού, αν και ποτέ δεν επιβεβαιώθηκε. Επίσημα η Summit Ridge είναι η πρώτη που τους χρησιμοποιεί και μάλιστα με την ονομασία Νευρωνικό Δίκτυο.
Επίσης στο υποσύστημα της πρόβλεψης μονοπατιού υπάρχει ένας πίνακας TLB (Translation Lookaside Buffer) στο οποίο αποθηκεύονται πρόσφατες μεταφράσεις εικονικών – φυσικών διευθύνσεων μνήμης για την μείωση καθυστερήσεων μετάφρασης, και λειτουργεί σε 3 επίπεδα. L0 με 8 καταχωρήσεις σελίδων ανεξαρτήτου μεγέθους, L1 με 64 καταχωρήσεις σελίδων ανεξαρτήτου μεγέθους και L2 με 512 σελίδες μεγέθους μόνο 4Κ ή 256Κ.
Όταν μια εντολή αναγνωρίζεται ως μια πρόσφατα χρησιμοποιούμενη, της ανατίθεται μια ετικέτα (micro tag) και πηγαίνει για προσωρινή αποθήκευση στην op cache, αλλιώς πηγαίνει παρακάτω για αποκωδικοποίηση. Η L1-Instruction Cache μπορεί επίσης να δεχτεί 32 byte / κύκλο ρολογιού από την L2 Cache καθώς άλλες εντολές περνάνε από την μονάδα Load / Store για τον επόμενο κύκλο εκτέλεσης.
Decode

Η L1-Instruction Cache στέλνει τα περιεχόμενά της στον αποκωδικοποιητή, ο οποίος μπορεί να αποκωδικοποιήσει 4 εντολές / κύκλο ρολογιού. Ο αποκωδικοποιητής έχει επίσης την δυνατότητα να ενώνει πολλαπλές εντολές υπό την σκέπη ενός κοινού micro-op. Αυτό έχει αποτέλεσμα μια θέση στην ουρά micro op να αντιστοιχεί σε πολλαπλές εντολές οι οποίες θα χωριστούν κατά την στιγμή της εκτέλεσης όταν φτάσουν στους χρονοπρογραμματιστές.
Μετά την ουρά micro op, έχουμε την Stack Engine. Αυτή βοηθάει στην παραγωγή διευθύνσεων μνήμης που είναι γνωστές από προηγούμενες εντολές με ελάχιστο ενεργειακό κόστος. Με αυτό τον τρόπο παρακάμπτεται το μονοπάτι των AGU και τις πρόσβασης στις μνήμες cache για γνωστές διευθύνσεις μνήμης.
Τέλος, ο Dispacher μπορεί να αποστείλει 6 εντολές / κύκλο και μέγιστο ρυθμό 6 εντολών / κύκλο για ακέραιους αριθμούς και 4 εντολών / κύκλο για αριθμούς κινητής υποδιαστολής καθώς και όποιο συνδυασμό μεταξύ των 2 ταυτόχρονα με συνολικό μέγιστο τις 6 εντολές / κύκλο.
Εκτέλεση, Load / Store, Χρονοπρογραμματισμός INT και FP

Στην είσοδο της μονάδας εκτέλεσης, έχουμε τις 6 micro op που απέστειλε το κύκλωμα αποκωδικοποίησης. Αυτές χωρίζονται σε εντολές ακεραίων και κινητής υποδιαστολής και αποστέλλονται στις κατάλληλες θέσεις. Πρώτη βρίσκεται η μονάδα ακεραίων η οποία διαθέτει ουρά 168 θέσεων και η οποία προωθεί τις εντολές σε 4 ALU (Arithmetic Logical Unit) και 2 AGU (Address Generation Unit). Επίσης κάθε ALU και AGU έχει την δικής ουρά 14 θέσεων. Αυτό επιτρέπει στον πυρήνα να χρονοδρομολογεί 6 micro op / κύκλο.
Η μονάδα ακεραίων παρακολουθεί τις εντολές διακλάδωσης με checkpoint, έτσι ώστε να μην αποθηκεύονται περιττά δεδομένα μεταξύ των κλάδων. Επίσης μπορεί να εκτελέσει Move Elimination. Αυτό είναι μια τεχνική με την οποία μια απλή εντολή mov μεταξύ δύο καταχωρητών χρησιμοποιείται αντί για μια δομή επανάληψης με τον οποία θα μετακινηθούν φυσικά τα δεδομένα. Με την εντολή mov τα δεδομένα μένουν στην θέση τους και απλά τροποποιούνται οι δείκτες προς τους καταχωρητές. Αυτό είναι ενεργειακά πιο αποδοτικό.

Η μονάδα Load / Store είναι προσβάσιμη και από τις 2 AGU ταυτόχρονα και υποστηρίζει 72 φορτώσεις εκτός σειράς. Συνολικά ο πυρήνας μπορεί να κάνει δύο 16Β φορτώσεις (2x128bit) και μία 16Β αποθήκευση ανά κύκλο.
Η L1-Data Cache επίσης έχει άμεση πρόσβαση στην L2 Cache με 32 Byte / κύκλο, με την 512KB 8-way L2 Cache να είναι ιδιωτική για κάθε πυρήνα.
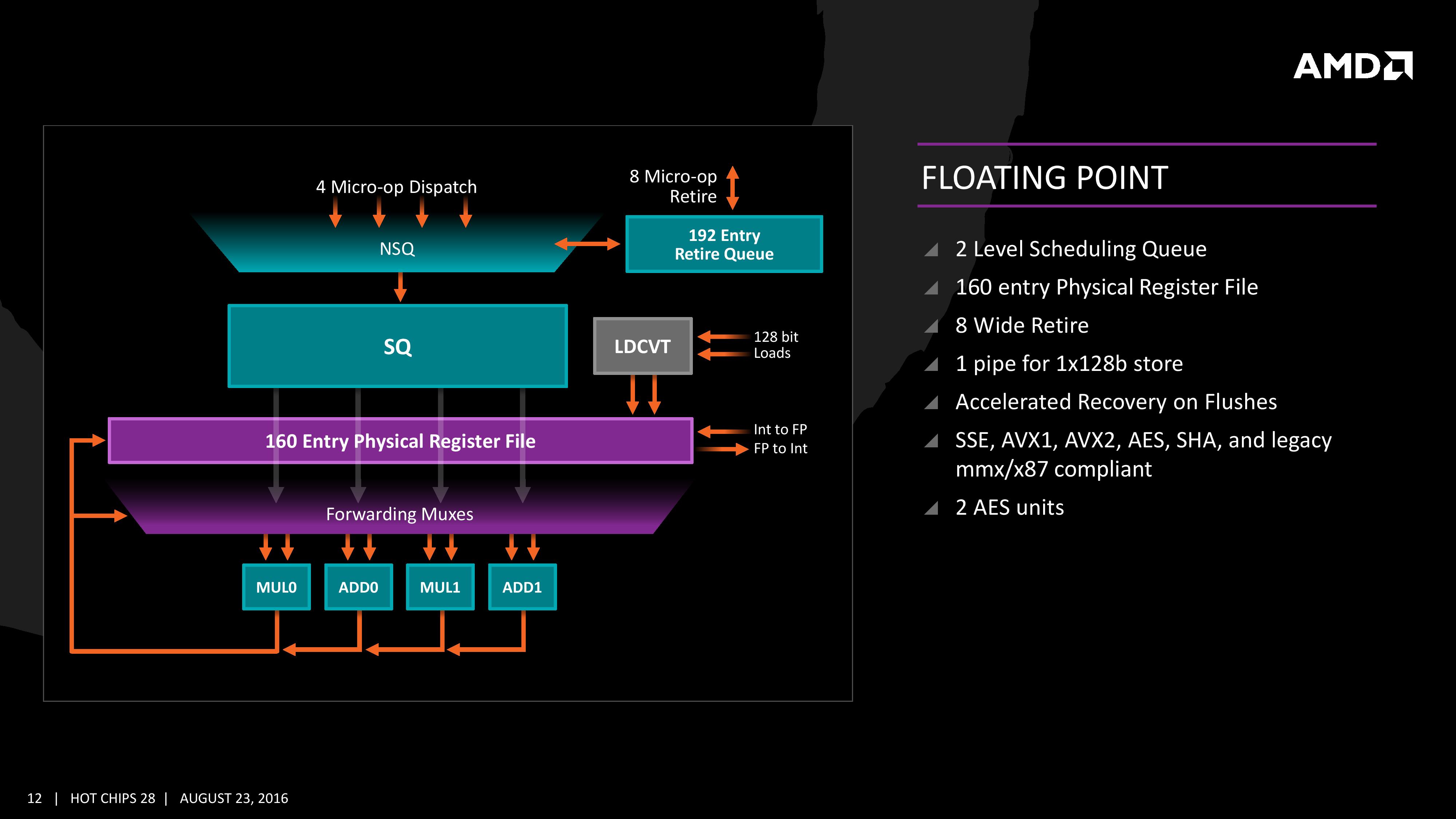
Πηγαίνοντας στο μέρος των αριθμών κινητής υποδιαστολής, βλέπουμε ότι η μονάδα αποτελείται από 4 ροές, 2 πρόσθεσης και 2 πολλαπλασιασμών. Αυτές είναι ικανές να συνδυαστούν για να εκτελέσουν μία 128bit FMAC εντολής. Οι εντολές 256bit AVX πρέπει να σπάσουν στα 2 όμως για να εκτελεστούν. Επίσης κάθε πυρήνας διαθέτει 2 μονάδες AES για εφαρμογές κρυπτογραφίας καθώς και αποκωδικοποίηση για SSE, AVX1, AVX2, SHA, MMX, X87.
CCX και Μνήμες Cache και Infinity Fabric
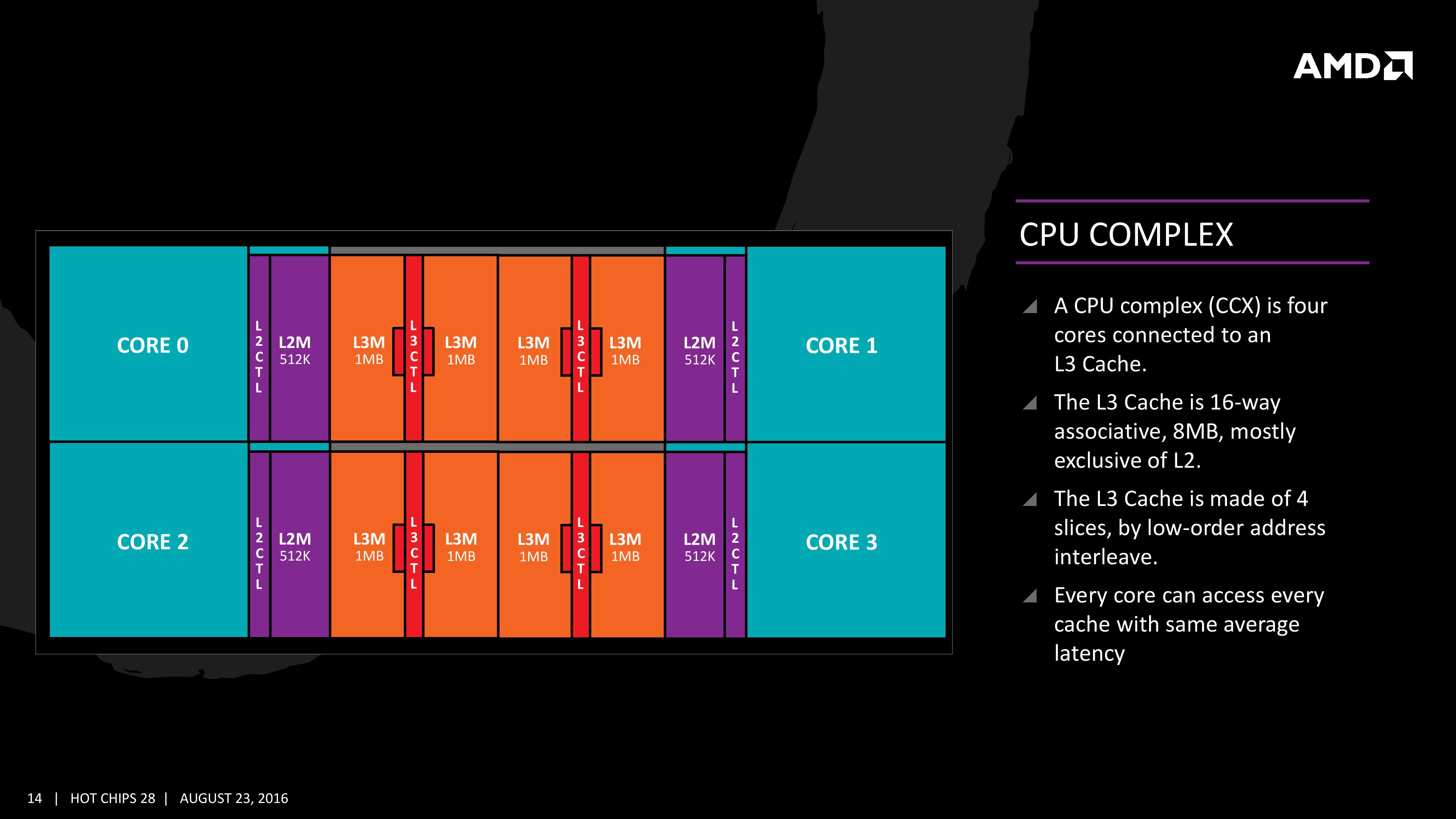
To CCX (Core Complex) είναι η βασική μονάδα της αρχιτεκτονικής Summit Ridge. Αυτή αποτελείται από 4 πυρήνες όμοιους με αυτόν που αναλύσαμε παραπάνω και τις μνήμες cache.
Κάθε πυρήνας έχει άμεση πρόσβαση στην ιδιωτική του L2 Cache. Τα 8 MB της L3 Cache είναι προσβάσιμα από όλους τους πυρήνες του CCX. Η L3 Cache είναι τύπου victim. Αυτό σημαίνει ότι γεμίζει με εντολές που αποσύρονται από τις L1 και L2 αντί για παίρνει δεδομένα από εντολές prefetch και demand.
Τα 8πύρηνα και 6πύρηνα μοντέλα των Ryzen που έχουν ήδη κυκλοφορήσει αποτελούνται ουσιαστικά από 2 CCX στο ίδιο die. Γι’ αυτό και τα 16MB Cache, αν και πρόκειται για 2×8 στην ουσία. Εξαίρεση αποτελούν οι 4πύρηνοι Ryzen 5 που αφού έχουν 8MB Cache ουσιαστικά πρόκεινται για 1 πλήρως λειτουργικό CCX.

Οι μνήμες Cache L1 και L2 είναι τοπικές για κάθε πυρήνα, και τα 8MB της L3 μοιράζεται ανάμεσα στους 4 πυρήνες του CCX. Η AMD δηλώνει ότι το bandwidth της L1 και L2 είναι 2x της αρχιτεκτονικής Excavator και για την L3 φτάνει και το 5x. Επίσης υπάρχουν μεγαλύτερες ουρές για τα cache misses στην L1 και L2.

Όλα τα υποσυστήματα του επεξεργαστή επικοινωνούν με ένα κεντρικό δίαυλο επικοινωνίας που η AMD ονομάζει “Infinity Fabric”. Για όσους είναι πιο γνώστες, είναι η εξέλιξη του διαύλου HyperTransport με νέες δυνατότητες που μπορεί να υποστηρίζει τις νέες γενιές CPU και GPU. Αυτός προσφέρει υψηλές ταχύτητες μεταγωγής και πολύ χαμηλή καθυστέρηση, κάτι πολύ σημαντικό μιας και έχουμε να κάνουμε με μια αρχιτεκτονική που βασίζεται στην επικοινωνία μεταξύ CCX, πυρήνων και cache που βρίσκονται σε διαφορετικά σημεία του die για να λειτουργήσει.

Simultaneous MultiThreading (SMT)

Η Summit Ridge είναι η πρώτη προσπάθεια της AMD στον πολυνηματισμό. Και το όνομα αυτού: SMT – Simultaneous MultiThreading. Ουσιαστικά πρόκειται για τον έξυπνο χρονοπρογραμματισμό νημάτων στο κάθε πυρήνα έτσι ώστε να φαίνεται ότι κάθε πυρήνας μπορεί να διαχειριστεί 2 νήματα. Είναι παρόμοια με την τεχνολογία της Intel ονόματι HyperThreading που πρωτοεμφανίστηκε στην αρχιτεκτονική Foster το 2002 στους Xeon και Pentium 4 που κυκλοφόρησαν τις χρονιές 2002 – 2004 και από το τον Νοέμβριο 2008 με το ντεμπούτο της Nehalem είναι πλέον σήμα κατατεθέν της Intel, αν και δεν είναι διαθέσιμη σε όλα τα μοντέλα της.
Υπάρχουν πολλοί τρόποι να διαχειριστούν τα νήματα σε έναν επεξεργαστή, ιδίως όταν πρόκειται για την αποφυγή φυσαλίδων κατά την ουρά εκτέλεσης που οδηγούν σε καθυστέρηση και κατάρρευση του συστήματος. Επίσης, οι drivers που αναλαμβάνουν την επικοινωνία του λειτουργικού συστήματος με τον επεξεργαστή πρέπει να αναγνωρίζουν και να ξεχωρίζουν τους φυσικούς από τους εικονικούς πυρήνες καθώς και να γνωρίζουν πότε ένα πυρήνας είναι κατειλημμένος. Έτσι έχουν τη δυνατότητα να πετύχουν μέγιστη απόδοση κατανέμοντας δύο νήματα ανά πυρήνα αλλά και αυξημένη αποδοτικότητα σε σενάρια χαμηλού φόρτου όπου και μπορούν να απενεργοποιήσουν ολόκληρα κομμάτια του επεξεργαστή εφόσον δεν χρειάζονται και να κατανείμουν τα νήματα σε όσα λειτουργούν.
Ο πιο βασικός τρόπος διαχωρισμού είναι η άμεση και αναλογική χρονοδρομολόγηση κάθε νήματος στον πυρήνα. Αυτός δεν είναι και ο καλύτερος τρόπος ιδίως σε σενάρια όπου τα νήματα σε κάποιο πυρήνα δεν έχουν παρόμοιο υπολογιστικό φόρτο ή κάποιο από τα νήματα είναι ευαίσθητο σε καθυστερήσεις ή κάποιο νήμα έχει πολλές φούσκες (χρόνους αναμονής π.χ. από έντονη χρήση I/O) κατά την εκτέλεσή του. Σε κάποιους τρόπους διαχωρισμού, υπάρχει η δυνατότητα να καθοριστεί η σημαντικότητα ενός νήματος και να λάβει κατάλληλη προτεραιότητα.
Σε κάθε νήμα, η AMD κάνει εσωτερική ανάλυση της ροής δεδομένων για να αντιληφθεί πιο νήμα έχει αλγοριθμική προτεραιότητα. Αυτό σημαίνει ότι κάποια νήματα έχουν ανάγκη από περισσότερους πόρους ή κάποια λανθασμένη διακλάδωση μονοπατιού πρέπει να πάρει προτεραιότητα για να αποφευχθούν έντονες καθυστερήσεις. Τα μπλέ μπόκ (Branch Prediction, Integer Rename, Floating Point Rename) λειτουργούν με αυτό τον τρόπο.
Επίσης ένα νήμα μπορεί να σημανθεί ως υψηλότερης προτεραιότητας. Αυτό είναι απαραίτητο για λειτουργίες ευαίσθητες στις χρονικές καθυστερήσεις όπως οθόνες αφής, είσοδο χρήστη κλπ. Οι TBL πίνακες δουλεύουν με αυτό τον τρόπο δίνοντας προτεραιότητα σε πρόσφατες μεταφράσεις διευθύνσεων μνήμης. Με τον ίδιο τρόπο επίσης δουλεύει και η Load Queue.
Μερικά τμήματα του επεξεργαστή έχουν στατική ανάθεση, δίνοντας σε κάθε νήμα ίσο χρόνο εκτέλεσης. Αυτό χρησιμοποιείται κυρίως σε εντολές που εκτελούνται με την σειρά, όπως για παράδειγμα οι έξοδοι του micro-op queue, της retire queue και store queue. Όμως, όταν το SMT είναι ενεργοποιημένο και υπάρχει μόνο ένα νήμα ανά πυρήνα τότε τα στατικά αναθετημένα τμήματα κοστίζουν σε χρόνο μιάς και δεν αξιοποιούνται πλήρως.
Η υπόλοιπη χρονοδρομολόγηση του πυρήνα γίνεται δυναμικά. Αυτό σημαίνει ότι εάν ένα νήμα απαιτήσει νέους πόρους, τότε θα προσπαθήσει να τους δεσμεύσει από τους υπάρχοντες ανενεργούς.
Νέες Εντολές

Η AMD εδώ έχει δυνητικά έναν άσσο στο μανίκι της, καθώς πέρα από το τυπικό ISA, υπάρχουν και μερικές νέες εντολές ειδικά για την Summit Ridge. Κάποιες από αυτές είναι οι SHA1, SHA256 για κρυπτογραφία, η CLZERO, η PTE Coalescing κ.α.
Η εντολή CLZERO καθαρίζει την γραμμή cache και απευθύνεται κυρίως σε media center και HPC εφαρμογές Αυτή επιτρέπει ένα νήμα να καθαρίζει σε ένα κύκλο ρολογιού μια λανθασμένη καταχώρηση στην cache.
Η εντολή PTE (Page Table Entry) Coalescing δίνει την δυνατότητα να συνδυάζονται 8 σελίδες 4K της cache σε μία 32Κ σελίδα. Αυτό είναι χρήσιμο γιατί μειώνει τον αριθμό των καταχωρήσεων στον πίνακα TLB και στις ουρές αναμονής.
Ισχύς και Αποδοτικότητα: SenseMI
Από τον προηγούμενο Αύγουστο ακόμα, όταν είδαμε τα πρώτα demo της Summit Ridge η AMD είχε δείξει ότι έχει εφάμιλλες επιδόσεις με την Broadwell-E της Intel με χαμηλότερη κατανάλωση ενέργειας.

Αυτή η αύξηση αποδοτικότητας +52% σε σχέση με την Bulldozer είναι αποτέλεσμα 5 καινοτομιών που η AMD βάζει υπό την σκέπη του όρου SenseMI. Στόχος είναι να δώσει στον επεξεργαστή ένα βαθμό νοημοσύνης έτσι ώστε να προσαρμόζεται στην εκάστοτε συνθήκες λειτουργίας.
1. Pure Power

Πολλοί νέοι επεξεργαστές έχουν αισθητήρες για την παρακολούθηση της λειτουργίας τους. Αλλά η AMD το πάει ένα βήμα παραπέρα. Χρησιμοποιεί αισθητήρες θερμοκρασίας, συχνότητας λειτουργίας και τάσης σε όλη την έκταση του die και χρησιμοποιεί το Infinity Fabric για τους ενώσει μεταξύ τους. Αυτό δίνει μια πολύ ακριβή εικόνα της θερμικής και ενεργειακής κατάστασης του chip που μπορεί να χρησιμοποιηθεί είτε για εξοικονόμηση ενέργειας είτε για αύξηση των επιδόσεων.
2. Precision Boost

Εδώ και αρκετά χρόνια, σχεδόν όλοι οι επεξεργαστές έχουν μεταβλητή συχνότητα λειτουργίας που τους επιτρέπει να έχουν χαμηλή κατανάλωση ενέργειας σε χαμηλό φόρτο χωρίς να χάνουν τις επιδόσεις τους όταν πιέζονται. Η Summit Ridge έχει την δυνατότητα να αλλάζει την συχνότητα λειτουργίας σε βήματα των 25 MHz που είναι το μικρότερο που έχουμε δει ποτέ.
Τα τρέχοντα συστήματα ρύθμισης συχνότητας και από την AMD και από την Intel αλλάζουν τον πολλαπλασιαστή για να αλλάξουν την συχνότητα. Με base clock 100 MHz, που έχουν όλοι οι σύγχρονοι επεξεργαστές, ένα βήμα στον πολλαπλασιαστή δίνει βήμα 100 MHz. Οπότε είναι ξεκάθαρο ότι το βήμα 25 MHz της Summit Ridge δίνει ακριβέστερο έλεγχο της τελικής συχνότητας.

Με πάνω από 1000 αισθητήρες συχνότητας, θερμοκρασίας και τάσης είναι πολύ πιο εύκολο να βρεθεί η ιδανική κατάσταση λειτουργίας, ιδίως αφού η Summit Ridge χειρίζεται την συχνότητα του κάθε πυρήνα ανεξάρτητα. Αυτό δίνει την δυνατότητα να ανακατευθυνθούν νήματα με μεγαλύτερες απαιτήσεις σε πόρους προς πυρήνες με μεγαλύτερη συχνότητα λειτουργίας.

3. Extended Frequency Range (XFR)

Όλοι οι τρέχοντες επεξεργαστές διαθέτουν σκάλες λειτουργίας οι οποίες αντιστοιχούν σε συγκεκριμένες συχνότητες λειτουργίας που μπορούν να επιλεχθούν από τον επεξεργαστή ή το OS ανάλογα από το επίπεδο επιδόσεων που απαιτείται. Η AMD με το XFR αφαιρεί αυτό τον περιορισμό και αφήνει απεριόριστη ρύθμιση του ρολογιού ανάλογα με τις συνθήκες λειτουργίας.
Στην θεωρία, αυτό θα επιτρέπει να αυξάνεται η συχνότητα λειτουργίας και πέρα από το Turbo Mode εφόσον παρέχεται αρκετή ψύξη, αν και κάποια στιγμή θα φτάσει τα όρια είτε τις κατανάλωσης ενέργειας, είτε του ίδιου του chip. Εκ πρώτης όψεως φαίνεται ότι είναι ή πρώτη προσπάθεια για τελείως αυτόματο και αυτόνομο overclocking.

4, 5. Neural Net Prediction και Smart Prefech
Κάθε νέα CPU που κυκλοφορεί υπόσχεται καλύτερο εντοπισμό μονοπατιού και καλύτερα μοντέλα για προ-ανάκληση εντολών. Όσο καλύτερα είναι αυτά τα 2, τόσο περισσότερο κρύβονται οι καθυστερήσεις που μπορεί να υπάρχουν κατα την αποκωδικοποίηση εντολών, μεταφορά δεδομένων μεταξύ μνημών κλπ.
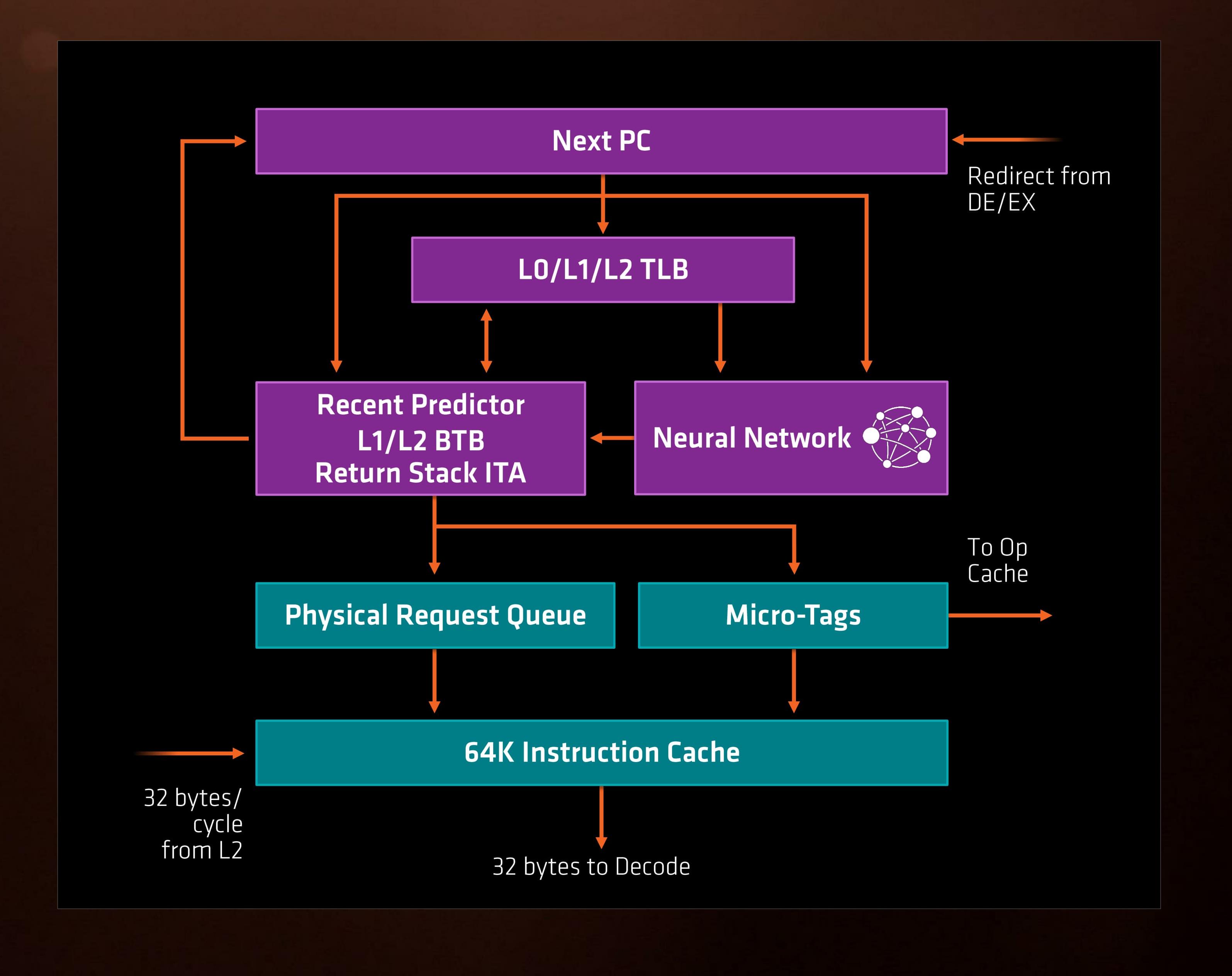
H AMD πλασάρει την δική της υλοποίηση της πρόβλεψης μονοπατιού ως ένα νευρωνικό δίκτυο, όπως είδαμε και πιο πάνω αναλυτικά.

Επίσης οι σύγχρονοι επεξεργαστές είναι αρκετά ικανοί να αντιλαμβάνονται πότε χρησιμοποιούνται επαναλαμβανόμενα δεδομένα και εντολές. Η παγίδα κρύβεται στο πόσο επιθετική θα είναι η πολιτική πρόβλεψης. Μια πολύ επιθετική πολιτική μπορεί να τραβάει δεδομένα που δεν θα χρησιμοποιηθούν ποτέ ξανά Από την άλλη μια πιο ήπια πολιτική μπορεί να μην τραβήξει όσα δεδομένα ξαναχρησιμοποιηθούν στο μέλλον. Και αυτή την χρυσή τομή κυνηγούνε πάντα και η AMD και η Intel.
H AMD δηλώνει ότι η Summit Ridge χρησιμοποιεί μοντέλα μηχανικής μάθησης για την πρόβλεψη μονοπατιού και προ-ανάκληση εντολών, αν και θα φανούν στην πράξη πόσο ακριβή είναι. Σε πρώτες δοκιμές πάντως που έχουν γίνει με όσα μοντέλα έχουν ήδη κυκλοφορήσει, έχουν παρατηρηθεί μικρές αυξήσεις απόδοσης σε επαναλαμβανόμενα επεξεργαστικά φορτία, οπότε οι ισχυρισμοί της AMD ότι η CPU μαθαίνει τι τρέχει και την επόμενη φορά το εκτελεί πιο αποδοτικά φαίνεται να στέκουν.
Επίλογος

Είναι πλέον ξεκάθαρο ότι η AMD δεν πήρε απλά και βελτίωσε της προγούμενη της αρχιτεκτονική, αλλά ξεκίνησε απο το μηδέν και έχτισε κάτι πολύ εντυπωσιακό, αναλογιζόμενοι το μέγεθος και την οικονομική κατάσταση της εταιρίας.
Από τους Ryzen 7 και 5 που έχουν κυκλοφορήσει ήδη βλέπουμε ότι οι επιδόσεις είναι άκρως ανταγωνιστικές με τους αντίστοιχους Intel σε αρκετά, πολλές φορές, χαμηλότερο κόστος. Αν και η Summit Ridge φτιάχτηκε ως ανταγωνίστρια της Broadwell-E, εν τούτις, σε ορισμένα σενάρια κοιτάει στα ίσια και ακόμα και ξεπερνάει τις Skylake και Kaby Lake.
H Summit Ridge αποδεικνύεται πραγματικό case study για το πώς η σκληρή δουλεία, η καινοτομία και η ιδιοφυία κάνουν στην άκρη το budget και παράγουν θαύματα. Επιτέλους η οκτάχρονη ηγεμονία του 4πύρηνου για τον μέσο χρήστη τελείωσε και όλα δείχνουν ότι πάμε για νέο πόλεμο στην αρένα των x86 επεξεργαστών. Και ως μηχανικός πληροφορικής και σκεπτόμενος καταναλωτής δεν θα μπορούσα παρά να είμαι χαρούμενος που ο ανταγωνισμός επέστρεψε.
Πηγές:
- https://arstechnica.co.uk/gadgets/2017/03/amd-zen-architecture/
- http://www.anandtech.com/show/11170/the-amd-zen-and-ryzen-7-review-a-deep-dive-on-1800x-1700x-and-1700
- https://www.pcgamesn.com/amd/amd-zen-release-date-specs-prices-rumours
- http://wccftech.com/amd-zen-architetcure-details/
- http://www.anandtech.com/show/10591/amd-zen-microarchiture-part-2-extracting-instructionlevel-parallelism/8
- http://hothardware.com/news/amd-ryzen-die-shot-cache-structure-architecture-advantages-exposed
- http://wccftech.com/amd-ryzen-architecture-detailed/
- https://en.wikipedia.org/wiki/Translation_lookaside_buffer
- https://en.wikipedia.org/wiki/Branch_target_predictor
- http://www-ee.eng.hawaii.edu/~tep/EE461/Notes/ILP/buffer.html
- https://en.wikipedia.org/wiki/Arithmetic_logic_unit
- https://en.wikipedia.org/wiki/Address_generation_unit
- https://www.quora.com/Floating-Point-How-does-Fused-Multiply-Add-FMA-work-and-what-is-its-importance-in-computing
- https://en.wikipedia.org/wiki/Perceptron



